 |
| 図 ◆政策,■政党.政策とそれに賛成する政党が近くにある…はず |
以下コード
|
| 図 ◆政策,■政党.政策とそれに賛成する政党が近くにある…はず |

brew install mongodb ==> Downloading http://fastdl.mongodb.org/osx/mongodb-osx-x86_64-2.2.2.tgz ######################################################################## 100.0% ==> Caveats To have launchd start mongodb at login: ln -sfv /usr/local/opt/mongodb/*.plist ~/Library/LaunchAgents Then to load mongodb now: launchctl load ~/Library/LaunchAgents/homebrew.mxcl.mongodb.plist Or, if you don't want/need launchctl, you can just run: mongod /usr/local/Cellar/mongodb/2.2.2-x86_64: 20 files, 170M, built in 98 seconds
ln -sfv /usr/local/opt/mongodb/*.plist ~/Library/LaunchAgents launchctl load ~/Library/LaunchAgents/homebrew.mxcl.mongodb.plist
mongod
mongo
> use mydb
switched to db mydb
> db
mydb
> j = {name: 'mongo'};
{ "name" : "mongo" }
> k = {x: 3}
{ "x" : 3 }
> db.things.insert(j)
> db.things.insert(k)
> show collections
system.indexes
things
> db.things.find()
{ "_id" : ObjectId("50caeb1fdab5ce4e84a41f78"), "name" : "mongo" }
{ "_id" : ObjectId("50caeb29dab5ce4e84a41f79"), "x" : 3 }
> for (var i = 1; i <= 20; i++) db.things.insert({x:4, j:i})
> db.things.find()
{ "_id" : ObjectId("50caeb1fdab5ce4e84a41f78"), "name" : "mongo" }
{ "_id" : ObjectId("50caeb29dab5ce4e84a41f79"), "x" : 3 }
{ "_id" : ObjectId("50caeee0dab5ce4e84a41f7a"), "x" : 4, "j" : 1 }
{ "_id" : ObjectId("50caeee0dab5ce4e84a41f7b"), "x" : 4, "j" : 2 }
{ "_id" : ObjectId("50caeee0dab5ce4e84a41f7c"), "x" : 4, "j" : 3 }
{ "_id" : ObjectId("50caeee0dab5ce4e84a41f7d"), "x" : 4, "j" : 4 }
{ "_id" : ObjectId("50caeee0dab5ce4e84a41f7e"), "x" : 4, "j" : 5 }
{ "_id" : ObjectId("50caeee0dab5ce4e84a41f7f"), "x" : 4, "j" : 6 }
{ "_id" : ObjectId("50caeee0dab5ce4e84a41f80"), "x" : 4, "j" : 7 }
{ "_id" : ObjectId("50caeee0dab5ce4e84a41f81"), "x" : 4, "j" : 8 }
{ "_id" : ObjectId("50caeee0dab5ce4e84a41f82"), "x" : 4, "j" : 9 }
{ "_id" : ObjectId("50caeee0dab5ce4e84a41f83"), "x" : 4, "j" : 10 }
{ "_id" : ObjectId("50caeee0dab5ce4e84a41f84"), "x" : 4, "j" : 11 }
{ "_id" : ObjectId("50caeee0dab5ce4e84a41f85"), "x" : 4, "j" : 12 }
{ "_id" : ObjectId("50caeee0dab5ce4e84a41f86"), "x" : 4, "j" : 13 }
{ "_id" : ObjectId("50caeee0dab5ce4e84a41f87"), "x" : 4, "j" : 14 }
{ "_id" : ObjectId("50caeee0dab5ce4e84a41f88"), "x" : 4, "j" : 15 }
{ "_id" : ObjectId("50caeee0dab5ce4e84a41f89"), "x" : 4, "j" : 16 }
{ "_id" : ObjectId("50caeee0dab5ce4e84a41f8a"), "x" : 4, "j" : 17 }
{ "_id" : ObjectId("50caeee0dab5ce4e84a41f8b"), "x" : 4, "j" : 18 }
Type "it" for more
> it
{ "_id" : ObjectId("50caeee0dab5ce4e84a41f8c"), "x" : 4, "j" : 19 }
{ "_id" : ObjectId("50caeee0dab5ce4e84a41f8d"), "x" : 4, "j" : 20 }
> var c = db.things.find()
> while (c.hasNext()) printjson(c.next())
{ "_id" : ObjectId("50caeb1fdab5ce4e84a41f78"), "name" : "mongo" }
{ "_id" : ObjectId("50caeb29dab5ce4e84a41f79"), "x" : 3 }
{ "_id" : ObjectId("50caeee0dab5ce4e84a41f7a"), "x" : 4, "j" : 1 }
{ "_id" : ObjectId("50caeee0dab5ce4e84a41f7b"), "x" : 4, "j" : 2 }
{ "_id" : ObjectId("50caeee0dab5ce4e84a41f7c"), "x" : 4, "j" : 3 }
{ "_id" : ObjectId("50caeee0dab5ce4e84a41f7d"), "x" : 4, "j" : 4 }
{ "_id" : ObjectId("50caeee0dab5ce4e84a41f7e"), "x" : 4, "j" : 5 }
{ "_id" : ObjectId("50caeee0dab5ce4e84a41f7f"), "x" : 4, "j" : 6 }
{ "_id" : ObjectId("50caeee0dab5ce4e84a41f80"), "x" : 4, "j" : 7 }
{ "_id" : ObjectId("50caeee0dab5ce4e84a41f81"), "x" : 4, "j" : 8 }
{ "_id" : ObjectId("50caeee0dab5ce4e84a41f82"), "x" : 4, "j" : 9 }
{ "_id" : ObjectId("50caeee0dab5ce4e84a41f83"), "x" : 4, "j" : 10 }
{ "_id" : ObjectId("50caeee0dab5ce4e84a41f84"), "x" : 4, "j" : 11 }
{ "_id" : ObjectId("50caeee0dab5ce4e84a41f85"), "x" : 4, "j" : 12 }
{ "_id" : ObjectId("50caeee0dab5ce4e84a41f86"), "x" : 4, "j" : 13 }
{ "_id" : ObjectId("50caeee0dab5ce4e84a41f87"), "x" : 4, "j" : 14 }
{ "_id" : ObjectId("50caeee0dab5ce4e84a41f88"), "x" : 4, "j" : 15 }
{ "_id" : ObjectId("50caeee0dab5ce4e84a41f89"), "x" : 4, "j" : 16 }
{ "_id" : ObjectId("50caeee0dab5ce4e84a41f8a"), "x" : 4, "j" : 17 }
{ "_id" : ObjectId("50caeee0dab5ce4e84a41f8b"), "x" : 4, "j" : 18 }
{ "_id" : ObjectId("50caeee0dab5ce4e84a41f8c"), "x" : 4, "j" : 19 }
{ "_id" : ObjectId("50caeee0dab5ce4e84a41f8d"), "x" : 4, "j" : 20 }
> var c = db.things.find()
> printjson(c[4])
{ "_id" : ObjectId("50caeee0dab5ce4e84a41f7c"), "x" : 4, "j" : 3 }
> c.toArray()
[
{
"_id" : ObjectId("50caeb1fdab5ce4e84a41f78"),
"name" : "mongo"
},
{
"_id" : ObjectId("50caeb29dab5ce4e84a41f79"),
"x" : 3
},
{
"_id" : ObjectId("50caeee0dab5ce4e84a41f7a"),
"x" : 4,
"j" : 1
},
{
"_id" : ObjectId("50caeee0dab5ce4e84a41f7b"),
"x" : 4,
"j" : 2
},
{
"_id" : ObjectId("50caeee0dab5ce4e84a41f7c"),
"x" : 4,
"j" : 3
},
{
"_id" : ObjectId("50caeee0dab5ce4e84a41f7d"),
"x" : 4,
"j" : 4
},
{
"_id" : ObjectId("50caeee0dab5ce4e84a41f7e"),
"x" : 4,
"j" : 5
},
{
"_id" : ObjectId("50caeee0dab5ce4e84a41f7f"),
"x" : 4,
"j" : 6
},
{
"_id" : ObjectId("50caeee0dab5ce4e84a41f80"),
"x" : 4,
"j" : 7
},
{
"_id" : ObjectId("50caeee0dab5ce4e84a41f81"),
"x" : 4,
"j" : 8
},
{
"_id" : ObjectId("50caeee0dab5ce4e84a41f82"),
"x" : 4,
"j" : 9
},
{
"_id" : ObjectId("50caeee0dab5ce4e84a41f83"),
"x" : 4,
"j" : 10
},
{
"_id" : ObjectId("50caeee0dab5ce4e84a41f84"),
"x" : 4,
"j" : 11
},
{
"_id" : ObjectId("50caeee0dab5ce4e84a41f85"),
"x" : 4,
"j" : 12
},
{
"_id" : ObjectId("50caeee0dab5ce4e84a41f86"),
"x" : 4,
"j" : 13
},
{
"_id" : ObjectId("50caeee0dab5ce4e84a41f87"),
"x" : 4,
"j" : 14
},
{
"_id" : ObjectId("50caeee0dab5ce4e84a41f88"),
"x" : 4,
"j" : 15
},
{
"_id" : ObjectId("50caeee0dab5ce4e84a41f89"),
"x" : 4,
"j" : 16
},
{
"_id" : ObjectId("50caeee0dab5ce4e84a41f8a"),
"x" : 4,
"j" : 17
},
{
"_id" : ObjectId("50caeee0dab5ce4e84a41f8b"),
"x" : 4,
"j" : 18
},
{
"_id" : ObjectId("50caeee0dab5ce4e84a41f8c"),
"x" : 4,
"j" : 19
},
{
"_id" : ObjectId("50caeee0dab5ce4e84a41f8d"),
"x" : 4,
"j" : 20
}
]
> db.things.find({name : "mongo"})
{ "_id" : ObjectId("50caeb1fdab5ce4e84a41f78"), "name" : "mongo" }
> db.things.find({x : 4}, {j : true})
{ "_id" : ObjectId("50caeee0dab5ce4e84a41f7a"), "j" : 1 }
{ "_id" : ObjectId("50caeee0dab5ce4e84a41f7b"), "j" : 2 }
{ "_id" : ObjectId("50caeee0dab5ce4e84a41f7c"), "j" : 3 }
{ "_id" : ObjectId("50caeee0dab5ce4e84a41f7d"), "j" : 4 }
{ "_id" : ObjectId("50caeee0dab5ce4e84a41f7e"), "j" : 5 }
{ "_id" : ObjectId("50caeee0dab5ce4e84a41f7f"), "j" : 6 }
{ "_id" : ObjectId("50caeee0dab5ce4e84a41f80"), "j" : 7 }
{ "_id" : ObjectId("50caeee0dab5ce4e84a41f81"), "j" : 8 }
{ "_id" : ObjectId("50caeee0dab5ce4e84a41f82"), "j" : 9 }
{ "_id" : ObjectId("50caeee0dab5ce4e84a41f83"), "j" : 10 }
{ "_id" : ObjectId("50caeee0dab5ce4e84a41f84"), "j" : 11 }
{ "_id" : ObjectId("50caeee0dab5ce4e84a41f85"), "j" : 12 }
{ "_id" : ObjectId("50caeee0dab5ce4e84a41f86"), "j" : 13 }
{ "_id" : ObjectId("50caeee0dab5ce4e84a41f87"), "j" : 14 }
{ "_id" : ObjectId("50caeee0dab5ce4e84a41f88"), "j" : 15 }
{ "_id" : ObjectId("50caeee0dab5ce4e84a41f89"), "j" : 16 }
{ "_id" : ObjectId("50caeee0dab5ce4e84a41f8a"), "j" : 17 }
{ "_id" : ObjectId("50caeee0dab5ce4e84a41f8b"), "j" : 18 }
{ "_id" : ObjectId("50caeee0dab5ce4e84a41f8c"), "j" : 19 }
{ "_id" : ObjectId("50caeee0dab5ce4e84a41f8d"), "j" : 20 }
> db.things.findOne()
{ "_id" : ObjectId("50caeb1fdab5ce4e84a41f78"), "name" : "mongo" }
> db.things.find().limit(3)
{ "_id" : ObjectId("50caeb1fdab5ce4e84a41f78"), "name" : "mongo" }
{ "_id" : ObjectId("50caeb29dab5ce4e84a41f79"), "x" : 3 }
{ "_id" : ObjectId("50caeee0dab5ce4e84a41f7a"), "x" : 4, "j" : 1 }
V = [[1,0,0,0],
[0,1,0,0],
[1,1,0,0],
[0,0,1,0],
[0,0,1,1]]というドキュメント(行が文、列が語)に対して、${\bf x}_{t+1} = f({\bf x}_t, {\bf u}_t) + {\bf w} \leftrightarrow p({\bf x}_{t+1}|{\bf x}_t, {\bf u}_t)\\
{\bf y}_t = g({\bf x}_t) + {\bf v} \leftrightarrow p({\bf y}_{t}|{\bf x}_t)$
$p({\bf x}_{t}|{\bf y}_{0:t}) \approx \sum_{i=1}^{N} w_t^{(i)} \cdot \delta ({\bf x}_t - {\bf x}_t^{(i)})$
2次元座標において、あるロボットが$t=0$に原点を出発して、速度$(4,4)$で動くとする。ロボットの進路は風などの影響を受け($\sigma_x=\sigma_y=2$),毎秒ごと4つの点$(0,0),(10,0),(0,10),(10,10)$からの距離を計測できて、計測には距離によらない誤差がある($\sigma_x=\sigma_y=4$)とする.このとき観測された軌跡から実際の軌跡を推定する.

for i in range(N): ${\bf x}_{t+1}^{(i)} \sim p({\bf x}_{t+1}^{(i)}|{\bf x}_{t}^{(i)}, {\bf u}_{t})$実際にはN個のパーティクルの位置を状態方程式に代入.
${\bf x}_{t+1}^{(i)} = f({\bf x}_{t}^{(i)}, {\bf u}_{t}) = {\bf A}{\bf x}_{t}^{(i)} + {\bf B}{\bf u}_{t} + {\bf w}$ただし
${\bf A} = \left[
\begin{array}{cc}
1 & 0 \\
0 & 1 \\
\end{array}
\right],
{\bf B} = \left[
\begin{array}{cc}
1 & 0 \\
0 & 1 \\
\end{array}
\right],
{\bf w} \sim N(0, 2{\bf I})$
for i in range(N): $w_{t+1}^{(i)} \leftarrow w_{t}^{(i)} \cdot p({\bf y}_{t+1}^{(i)}|{\bf x}_{t+1}^{(i)})$尤度関数によって重みを更新.$\sum^i w_{t+1}^{(i)} = 1$で正規化.今回はモデルを正規分布にしたのでRBFカーネルで.尤度関数は推定値と観測値が似てれば似てるほど大きくなるように設定.物体追跡検知とかだと色の情報を使う.
$p({\bf y}_{t+1}^{(i)}|{\bf x}_{t+1}^{(i)}) \propto \exp(-\frac{(y-g(x))^2}{\sigma^2})$ただし
$g({\bf x}) = \left[ ||{\bf x}-{\bf p}_1||, ||{\bf x}-{\bf p}_2||, ||{\bf x}-{\bf p}_3||, ||{\bf x}-{\bf p}_4|| \right]^{\mathsf{T}}\\
{\bf p}_1=\left[0, 0\right]^{\mathsf{T}}, {\bf p}_2=\left[10, 0\right]^{\mathsf{T}}, {\bf p}_3=\left[0, 10\right]^{\mathsf{T}}, {\bf p}_4=\left[10, 10\right]^{\mathsf{T}} \\
\sigma^2 = 4$
$\{ {\bf x}_{t+1}^{(i)}, w_{t+1}^{(i)}=1 \} \leftarrow resampling(\{ {\bf x}_{t+1}^{(i)}, w_{t+1}^{(i)} \})$重みに応じてリサンプリング.重みが偏らないように.毎回やる必要はない.色々手法があるらしいけど今回は単純に多項分布でサンプリング.
http://www.cs.princeton.edu/~blei/lda-c/
tar xvfz lda-c-dist.tgz tar xvfz ap.tgz cd lda-c-dist make
[M] [term_1]:[count] [term_2]:[count] ... [term_N]:[count]たとえば
% head -n 3 ../ap/ap.dat1つ目のドキュメントは,語が186種類,語0が1回,語6144が1回…
186 0:1 6144:1 3586:2 3:1 4:1 ...
174 68:1 512:1 514:2 3:1 4:1 ...
161 0:9 68:1 1538:1 3588:1 517:1 ...
./lda est 1.0 50 settings.txt ../ap/ap.dat random testtestフォルダ以下に結果が出力されます.引数は,LDAのパイパーパラメータ$\alpha$,トピック数$K$,設定ファイル,データセット,初期状態,出力先.
./lda inf settings.txt test/final ../ap/ap.dat inference出力はinference-gamma.dat,inference-lda-lhood.dat.
python topics.py test/final.beta ../ap/vocab.txt 10
http://gibbslda.sourceforge.net/
tar xvfz GibbsLDA++-0.2.tar.gz cd GibbsLDA++-0.2 make clean make all
[M]
[document1]
[document2]
...
[documentM]
[documenti] = [wordi1] [wordi2] ... [wordiNi]たとえば
% head -n3 trndocs.dat
1000
abil absenc acquisit acquisit agreem ...
activ ball ball band brief ...
src/lda -est -alpha 0.5 -beta 0.1 -ntopics 100 -niters 1000 -savestep 100 -twords 20 -dfile models/casestudy/trndocs.datestでLDAのパラメータを推定します.LDAのハイパーパラメータalpha,beta,トピック数ntopics,繰り返し回数niters,ステップsavestep,出力語数twords,データdfile.twordsを指定すると,各トピックの特徴語が出力されます.
src/lda -estc -dir models/casestudy/ -model model-01000 -niters 800 -savestep 100 -twords 30estcで指定したモデルからパラメータを推定します.
src/lda -inf -dir models/casestudy/ -model model-01800 -niters 30 -twords 20 -dfile newdocs.datinfで作ったモデルから他のデータセットの推定をします.
http://code.google.com/p/plda/
tar xvfz plda-3.0.tar.gz cd plda make lda infer
[word1] [word1_count] [word2] [word2_count] [word3] [word3_count] ...たとえば
% head -n3 testdata/test_data.txt
concept 1 consider 1 global 1 entropy 1 go 1 ...
externally 1 global 1 dynamic 1 resistance 1 illustrated 1 ...
consider 1 chain 1 global 1 leads 1 go 1 ...
./lda --num_topics 2 --alpha 0.1 --beta 0.01 --training_data_file testdata/test_data.txt --model_file testdata/lda_model.txt --burn_in_iterations 100 --total_iterations 150パラメータは上のものと似たようなもん.testdata/lda_model.txtに出力.出力のそれぞれの行は語のトピックの分布を表す.たとえば
% head -n3 testdata/lda_model.txt
concept 179.3 2.7
consider 921.98 0.02
global 296.3 180.7
python view_model.py testdata/lda_model.txt
./infer --alpha 0.1 --beta 0.01 --inference_data_file testdata/test_data.txt --inference_result_file testdata/inference_result.txt --model_file testdata/lda_model.txt --total_iterations 15 --burn_in_iterations 10alphaは訓練の時と同じものを使いましょう.

http://twitter.com/aozoramakura
[書き出し] [カードへのリンク] #aozoramakuraってつぶやく.
[{u'ebk': u'',
u'html': u'http://www.aozora.gr.jp/cards/001235/files/49858_41918.html',
u'jinbutsu': u'001235',
u'sakuhin': u'49858',
u'text': u'\u3042\u308b\u4eba\u3073\u3068\u306f\u3001\u300c\u30aa\u30c9\u30e9\u30c7\u30af\u300d\u3068\u3044\u3046\u8a00\u8449\u306f\u30b9\u30e9\u30f4\u8a9e\u304b\u3089\u51fa\u3066\u3044\u308b\u3001\u3068\u3044\u3063\u3066\u3001\u305d\u308c\u3092\u6839\u62e0\u306b\u3057\u3066\u3053\u306e\u8a00\u8449\u306e\u6210\u7acb\u3092\u8a3c\u660e\u3057\u3088\u3046\u3068\u3057\u3066\u3044\u308b\u3002'}, ...]


$ enable-app-engine-project .
X-AppEngine-Cron: true

Frontend Instance Hours 4% 1.01 of 28.00 Instance Hours
Code and Static File Storage 1% 0.01 of 1.00 GBytes

あおぞらまくら
% makeで実行ファイル svm-scale, svm-train, svm-predict が生成されます.Windowsでのやり方もREADMEを見れば書いてあると思います.どこでも実行できるようにするためにはPATHの通った場所に置く必要がありますが,今回は別に移動しなくても大丈夫.
% which gnuplotであったらeasy.pyの19行目を以下のように変更します.
/usr/local/bin/gnuplot
gnuplot_exe = "/usr/bin/gnuplot"
gnuplot_exe = "/usr/local/bin/gnuplot"
<label> <index1>:<value1> <index2>:<value2> …インデックスは1から始まることに注意.たとえばnode0のインデックスは1,node1のインデックスは2.
.
.
.
% cat links
1 1:1 3:1 5:1 10:1
1 1:1 2:1 3:1 4:1
1 1:1 4:1 5:1
-1 6:1 10:1
-1 4:1 7:1 8:1 9:1
-1 7:1 8:1 10:1
% cat links.t
1 1:1 3:1 5:1 10:1
0 2:1 3:1
1 1:1 2:1 3:1 4:1
0 3:1 4:1 5:1 7:1
1 1:1 4:1 5:1
-1 6:1 10:1
-1 4:1 7:1 8:1 9:1
-1 7:1 8:1 10:1
0 7:1 9:1
0 1:1 6:1 8:1 10:1
% cd tools
% ./easy.py links links.t
% cat links.t.predict
1
1
1
1
1
-1
-1
-1
-1
-1
Excelでマクロを使用して散布図またはバブルチャートのデータポイントにラベルを追加する方法 http://support.microsoft.com/kb/213750/ja












| ||||||||||
$\begin{align}
J({\bf f})&=\sum_{i=1}^l(y^{(i)}-f^{(i)})^2 + \lambda \sum_{i<j}y^{(i,j)}(f^{(i)}-f^{(j)})^2 \\
&=||{\bf y}-{\bf f}||_2^2+\lambda {\bf f}^T{\bf L}{\bf f}
\end{align}$
$({\bf I}+\lambda {\bf L}){\bf f}={\bf y}$
% gem update heroku
% heroku addons:add pgbackups --app foo
% heroku addons:add pgbackups --app bar
% heroku pgbackups:capture --app foo
% heroku pgbackups:restore DATABASE `heroku pgbackups:url --app foo` --app bar
gem 'omniauth'で
gem 'omniauth-twitter'
bundle install
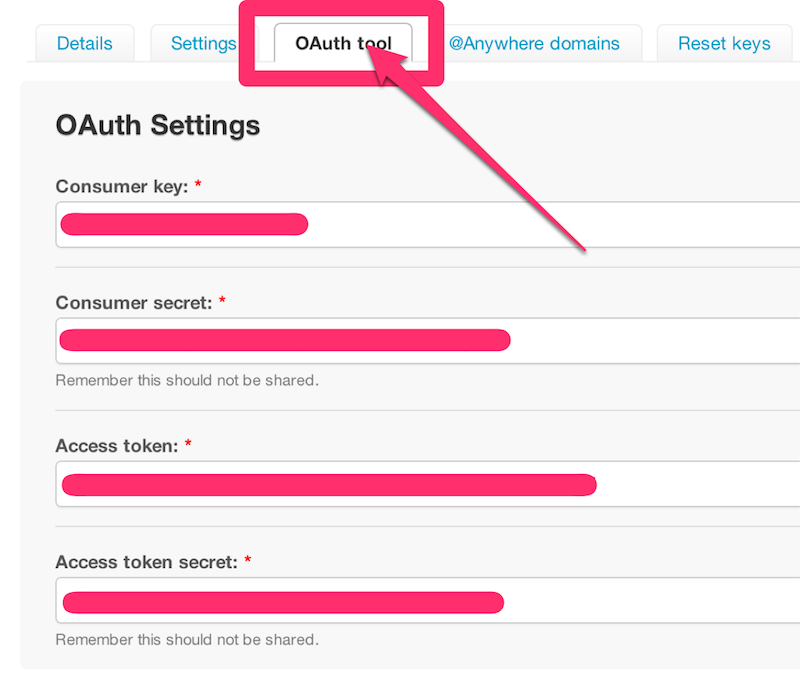
% cat config/initializers/omniauth.rb Rails.application.config.middleware.use OmniAuth::Builder do provider :twitter, '[Consumer key]', '[Consumer secret]' end[Consumer key]と[Consumer secret]は上で取得したものを設定
rails g model user provider:string uid:string name:string screen_name:string
rake db:migrate
% cat app/models/user.rb
class User < ActiveRecord::Base
def self.create_with_omniauth(auth)
create! do |user|
user.provider = auth['provider']
user.uid = auth['uid']
user.name = auth['info']['name']
user.screen_name = auth['info']['nickname']
end
end
end
rails g controller sessions
% cat app/controllers/sessions_controller.rb
class SessionsController < ApplicationController
def callback
auth = request.env["omniauth.auth"]
user = User.find_by_provider_and_uid(auth["provider"], auth["uid"]) || User.create_with_omniauth(auth)
session[:user_id] = user.id
redirect_to root_path, :notice => "Logged in"
end
def destroy
session[:user_id] = nil
redirect_to root_path, :notice => "Logged out"
end
end
rails g controller welcome index
% cat app/views/layouts/application.html.erb
<!DOCTYPE html>
<html>
<head>
<title>Omniauth</title>
<%= stylesheet_link_tag "application", :media => "all" %>
<%= javascript_include_tag "application" %>
<%= csrf_meta_tags %>
</head>
<body>
<% if current_user %>
<%= current_user.name %>
<%= current_user.screen_name %>
<%= link_to 'Log out', logout_path %>
<% else %>
<%= link_to 'Log in', '/auth/twitter' %>
<% end %>
<%= yield %>
</body>
</html>
% cat app/controllers/application_controller.rb
class ApplicationController < ActionController::Base
protect_from_forgery
def login_required
if session[:user_id]
@current_user = User.find(session[:user_id])
else
redirect_to root_path
end
end
helper_method :current_user
private
def current_user
@current_user ||= User.find(session[:user_id]) if session[:user_id]
end
end
% cat config/routes.rb Omniauth::Application.routes.draw do get "welcome/index" match "/auth/:provider/callback" => "sessions#callback" match "/logout" => "sessions#destroy", :as => :logout root :to => 'welcome#index' end
% diff /etc/apache2/httpd.conf /etc/apache2/httpd.conf.default
145c145
< LoadModule python_module libexec/apache2/mod_python.so
---
> #LoadModule python_module libexec/apache2/mod_python.so
469c469
< AddHandler cgi-script .cgi .py
---
> #AddHandler cgi-script .cgi
% diff /etc/apache2/users/hoge.conf /etc/apache2/users/hoge.conf.default
2c2
< Options Indexes MultiViews ExecCGI
---
> Options Indexes MultiViews
/Users/hoge/Sites% cat hello.py
#!/usr/bin/python
# -*- coding: utf-8 -*-
print "Content-Type: text/plain"
print "Hello world!"
/Users/hoge/Sites% chmod 755 hello.py
System Preferences → Keyboard → Keyboard Shortcuts → Services





訓練データ(ユーザとアイテムとユーザがアイテムをフォローしたかどうか)とユーザ・アイテムのデータを使って,テストデータ(ユーザとアイテム)が与えられてたら推薦度を推定する,
(UserId)\t(ItemId)\t(Result)\t(Unix-timestamp)
% head rec_log_train.txt 2088948 1760350 -1 1318348785 2088948 1774722 -1 1318348785 2088948 786313 -1 1318348785 601635 1775029 -1 1318348785 601635 1902321 -1 1318348785 601635 462104 -1 1318348785 1529353 1774509 -1 1318348786 1529353 1774717 -1 1318348786 1529353 1775024 -1 1318348786 1853982 1760403 -1 1318348789
(UserId)\t(Year-of-birth)\t(Gender)\t(Number-of-tweet)\t(Tag-Ids)
% head user_profile.txt 100044 1899 1 5 831;55;198;8;450;7;39;5;111 100054 1987 2 6 0 100065 1989 1 57 0 100080 1986 1 31 113;41;44;48;91;96;42;79;92;35 100086 1986 1 129 0 100097 1981 1 75 0 100100 1984 1 47 71;51 100101 2003 1 31 0 100116 1988 2 39 35 100117 2009 2 37 0
(ItemId)\t(Item-Category)\t(Item-Keyword)
% head item.txt 2335869 8.1.4.2 412042;974;85658;174033;974;9525;72246;39928;8895;30066;2245;1670;85658;174033;6977;6183;974;85658;174033;974;9525;72246;39928;8895;30066;2245;1670;85658;174033;6977;6183;974 1774844 1.8.3.6 31449;517124;45008;2796;79868;45008;202761;2796;101376;144894;31449;327552;133996;17409;2796;4986;2887;31449;6183;2796;79868;45008;13157;16541;2796;17027;2796;2896;4109;501517;2487;2184;9089;17979;9268;2796;79868;45008;202761;2796;101376;144894;31449;327552;133996;17409;2796;4986;2887;31449;6183;2796;79868;45008;13157;16541;2796;17027;2796;2896;4109;501517;2487;2184;9089;17979;9268 1775000 1.4.2.4 259580;626835;12152;6183;561;10666;12152;6183;561;60774;21206;561;160212;539;2225;320443;12152;6183;561;10666;12152;6183;561;60774;21206;561;160212;539;2225;320443 1775024 1.4.1.4 498354;61029;60774;12318;3825;465;5788;6183;561;61029;539;71940;335;27;60774;12318;3825;465;5788;6183;561;61029;539;71940;335;27 1774455 1.4.1.2 155009;345081;12203;6183;561;9642;12203;561;3203;40075;539;345081;26124;10638;490970;12203;6183;561;9642;12203;561;3203;40075;539;345081;26124;10638;490970 1775040 1.4.2.2 100947;97714;12203;6183;3203;45782;12203;3203;46868;13;97714;12203;6183;3203;45782;12203;3203;46868;13;97714 1774505 1.4.9.2 254337;195099;974;12203;6183;974;11354;12203;974;37888;17713;62372;454;974;12203;6183;974;11354;12203;974;37888;17713;62372;454;974 1774776 8.1.4.2 239661;974;46479;17713;974;14461;46479;17713;974;31325;610;46441;143118;208450;5647;35944;70488;307170;175621;326588;46479;17713;974;14461;46479;17713;974;31325;610;46441;143118;208450;5647;35944;70488;307170;175621;326588 495072 8.1.4.2 296259;596521;4861;4385;31325;31693;12152;974;35133;205881;474444;1100;115394;76462;636390;112571;75629;4861;35639;4385;31325;136353;87610;93388;159442;146683;300971;4861;4385;31325;31693;12152;974;35133;205881;474444;1100;115394;76462;636390;112571;75629;4861;35639;4385;31325;136353;87610;93388;159442;146683;300971 2076876 1.4.9.2 239661;974;428257;6183;68271;974;6254;46479;17713;36169;6183;68271;974;50048;68271;125744;41791;30825;31325;46479;17713;60765;490251;3824;22793;102745;288673;6183;68271;974;6254;46479;17713;36169;6183;68271;974;50048;68271;125744;41791;30825;31325;46479;17713;60765;490251;3824;22793;102745;288673
(UserId)\t(Action-Destination-UserId)\t(Number-of-at-action)\t(Number-of-retweet )\t(Number-of-comment)
“A B 3 5 6”だったら,AのBへの @つきアクション(リプライ?メンション?)が3回,リツイート5回,コメントが6回.
% head user_action.txt 1000004 1000004 0 3 4 1000004 1290320 0 3 0 1000004 1675399 0 1 0 1000004 1760423 0 1 0 1000004 1774718 0 1 0 1000004 1774862 0 1 0 1000004 1775076 0 1 0 1000004 1837210 0 1 0 1000004 1928681 0 1 0 1000004 1954203 0 1 0
(Follower-userid)\t(Followee-userid)
% head user_sns.txt 1000001 373407 1000001 461001 1000001 692475 1000002 1760423 1000002 1760426 1000002 1760642 1000002 1774712 1000002 1774861 1000002 1774957 1000002 1774963
(UserId)\t(Keywords)
% head user_key_word.txt 1000000 183:0.6673;2:0.3535;359:0.304;363:0.1835;377:0.1831;10:0.1747;58:0.1725;127:0.1624;459:0.1482;54:0.142;330:0.1361;1480:0.1358;40:0.1136;672:0.1037 1000001 92:1.0 1000002 112:1.0 1000003 154435:0.746;30:0.3902;220:0.2803;238:0.2781;232:0.2717;1928:0.2479 1000004 118:1.0 1000005 157:0.484;25:0.4383;198:0.3033;185:0.3012;31:0.2991;80:0.2971;203:0.241;34:0.2347;95:0.2327;37:0.214 1000006 277:0.7815;1980:0.4825;146:0.175;103:0.1475;83:0.1382;107:0.1061;892:0.1019 1000007 4069:0.6678;2557:0.6104;137:0.4261 1000008 16:0.7164;154:0.3278;164:0.3222;246:0.2258;17:0.1943;14:0.1789;340:0.1789;366:0.1719;139:0.1587;279301:0.1139;484:0.1083;116:0.1055;193:0.1027
(UserId)\t(ItemId)\t(Prediction)
ap@n = Σ k=1,...,n P(k) / (number of items clicked in m items)
AP@n = Σ i=1,...,N ap@ni / N
% head rec_log_test.txt 1449438 1394821 0 1321027200 1449438 372323 0 1321027200 1525431 1774707 0 1321027200 1587150 1774422 0 1321027200 1587150 1774934 0 1321027200 2064344 1505267 0 1321027200 2081969 1760410 0 1321027200 2141596 1760376 0 1321027200 2359607 1606609 0 1321027200 2359607 2105484 0 1321027200
% head sub_small_header.csv id,clicks 100001,647356 458026 1606609 100004,647356 1606574 1774568 100005,1606574 1774532 586592 100009,647356 1760327 1606574 100010,458026 2105511 713225 100011,1774594 1774717 1774505 100012,458026 2105511 727272 100013,1870054 514413 1760401 100014,859545 2167615 715470
% head sub_min.csv 647356 458026 1606609 647356 1606574 1774568 1606574 1774532 586592 647356 1760327 1606574 458026 2105511 713225 1774594 1774717 1774505 458026 2105511 727272 1870054 514413 1760401 859545 2167615 715470 647356 458026 1606574
$\begin{align}というように表され,$\{{\bf y}_1,...,{\bf y}_T\}$が与えられたときに,$A,C,Q,R$と初期状態の平均ベクトル$\pi_1$と分散共分散行列$V_1$を推定します.
{\bf x}_{t+1}&=A{\bf x}_t + {\bf w}_t\\
{\bf y}_{t}&=C{\bf x}_t + {\bf v}_t\\
{\bf w}_t &\sim N(0,Q)\\
{\bf v}_t &\sim N(0,R)\\
\end{align}$
$\begin{align}
{\bf x}_t^{\tau}&=E({\bf x}_t|\{{\bf y}_1^{\tau}\})\\
V_t^{\tau}&=Var({\bf x}_t|\{{\bf y}_1^{\tau}\})\\
\end{align}$
$\begin{align}
{\bf x}_1^0 &= {\bf \pi}_1\\
V_1^0 &= V_1\\
{\bf x}_t^{t-1} &= A {\bf x}_{t-1}^{t-1}\\
V_t^{t-1} &= A V_{t-1}^{t-1} A' + Q\\
K_t &= V_t^{t-1}C'(CV_t^{t-1}C'+R)^{-1}\\
{\bf x}_t^t &= {\bf x}_t^{t-1} + K_t({\bf y}_t-C{\bf x}_t^{t-1})\\
V_t^t &= V_t^{t-1} - K_t C V_t^{t-1}\\
\end{align}$
$\begin{align}
J_{t-1} &= V_{t-1}^{t-1}A'(V_t^{t-1})^{-1}\\
{\bf x}_{t-1}^T &= {\bf x}_{t-1}^{t-1} + J_{t-1}({\bf x}_t^T - A{\bf x}_{t-1}^{t-1})\\
V_{t-1}^T &= V_{t-1}^{t-1} + J_{t-1}(V_t^T - V_t^{t-1})J_{t-1}'\\
V_{T,T-1}^T &= (I - K_T C)AV_{T-1}^{T-1}\\
V_{t-1,t-2}^T &= V_{t-1}^{t-1}J_{t-2}' + J_t-1(V_{t,t-1}^T - AV_{t-1}^{t-1})J_{t-2}'\\
\end{align}$
$\begin{align}
{\hat {\bf x}}_t & = {\bf x}_t^T \\
P_t & = V_t^T + {\bf x}_t^T {{\bf x}_t^T}' \\
P_{t,t-1} & = V_{t,t-1}^T + {\bf x}_t^T{{\bf x}_{t-1}^T}' \\
\end{align}$
$\begin{align}なおN個の観測列があるときは
C^{new} & = (\sum_{t=1}^T {\bf y}_t {\hat{\bf x}}_t')(\sum_{t=1}^T P_t)^{-1} \\
R^{new} & = \frac{1}{T}\sum_{t=1}^T({\bf y}_t{\bf y}_t' - C^{new}{\hat{\bf x}}_t{\bf y}_t') \\
A^{new} & = (\sum_{t=2}^T P_{t,t-1})(\sum_{t=2}^T P_{t-1})^{-1} \\
Q^{new} & = \frac{1}{T-1}(\sum_{t=2}^T P_{t} - A^{new}\sum_{t=2}^T P_{t-1,t}) \\
{\bf \pi}_1^{new} & = {\hat {\bf x}}_1 \\
V_1^{new} & = P_1 - {\hat {\bf x}}_1{\hat {\bf x}}_1'
\end{align}$
$\begin{align}
{\bar {\hat {\bf x}}}_t & = \frac{1}{N}\sum_{i=1}^N {\hat {\bf x}}_t^{(i)} \\
V_1^{new} & = P_1 - {\bar {\hat {\bf x}}}_1{\bar {\hat {\bf x}}}_1' + \frac{1}{N}\sum_{i=1}^N [{\bar {\hat {\bf x}}}_1^{(i)}-{\bar {\hat {\bf x}}}_1][{\bar {\hat {\bf x}}}_1^{(i)}-{\bar {\hat {\bf x}}}_1]' \\
\end{align}$
A [[ 1. 0.1] [ 0. 1. ]] C [[ 1. 0.]] Q [[ 2.50000000e-05 5.00000000e-04] [ 5.00000000e-04 1.00000000e-02]] R [[ 1.]]でした.
A [[ 0.62656567 0.64773696] [ 0.56148647 0.0486408 ]] C [[ 0.19605285 1.14560846]] Q [[ 0.15479875 -0.12660499] [-0.12665761 0.31297647]] R [[ 0.59216228]] pi_1 [[-0.39133729] [-0.89786661]] V_1 [[ 0.18260503 -0.07688508] [-0.07691364 0.20206351]]でした.下のコードでは生成されるデータは毎回異なるので結果はその都度変わります.がどうもうまくいかない.




















/usr/bin/ruby -e "$(curl -fsSL https://raw.github.com/gist/323731)"要Intel CPU,OS X 10.5 or higher,Xcode with X11,Java Developer Update.
brew install fontforge2行目のシンボリックリンクの張り方はFontForgeインストール後に表示される.
ln -s /usr/local/Cellar/fontforge/20110222/FontForge.app /Applications
brew install ghostscript
easy_install pipeasy_installのかわり.アンインストールもできる.




